iPToL_Progress
iPlant Tree of Life (iPToL) Grand Challenge Project Progress Report
In May 2009, the iPToL Grand Challenge Project Kickoff meeting was held at NESCent to establish specific areas of focus and to develop a high-level implementation plan for the iPToL project. From this meeting, it was decided to divide the grand challenge into six focal areas, each corresponding to a specific working group. Leads and co-leads for each working group were recommended by consensus and working group membership was drafted from both meeting participants and non-participating community members. During the kickoff meeting, support was expressed for two other possible collaborations: upgrading the Angiosperm Phylogeny Web Site (APWEB2) and the Botanical Information and Ecology Network (BIEN). By consensus, these were determined not to be within the scope of the core iPToL budget but a desire to support these efforts was agreed. In the fall of 2009, new collaborations were established with these groups, with additional funding added to the iPToL budget. The APWEB2 project is regarded as an Education Outreach and Training (EOT) extension of the iPToL project. The BIEN collaboration has now become part of iPToL and is meant as an expanded solution to the pervasive "taxonomic intelligence" problem (described below) and will also help to integrate ecological trait data with iPToL’s discovery environments.
Working Groups
Big Trees: Scaling up Phylogenetic Inference
Phylogenetic analysis at the level of several hundred thousand species represents a new scalability challenge that iPlant is addressing on two parallel tracks. The general approach is to optimize existing methods (using Maximum Likelihood with RAxML and Neighbor-Joining with NINJA/WINDJAMMER). The current testing data set is a matrix of eight genes for 116K species provided by Stephen Smith. The necessity of using very large data matrices and measuring uncertainty using bootstrap replicate analysis make scaling up to the ultimate goal of building phylogenetic trees for up to 500,000 species a formidable challenge that requires high performance computing (HPC) methods to be able to perform and update the analysis in tractable amounts of time. Data for the full 500,000 green plants are not yet available, though this is the mission of the data assembly working group, described below. When the data become available, we wish to have the infrastructure already in place to cope with them. One area of concern in the big tree groups was that outward communication has been limited. We have now established regular meetings between the TACC members of the big tree group with the external collaborators to improve communication and ensure user requirements are being met.
RAxML
RAxML was developed by Alexandros Stamatakis. John Cazes and B. D. Kim, members of the iPlant engagement team at TACC have been working to scale up the application to be able to leverage the substantial TACC high performance computing resources.
The first major achievement for this work is the addition of check-pointing to allow stopping and restarting of long-running processing jobs without loss of data or compute time. Ongoing work is being done to improve parallel implementation and to decrease overall run-time for large data sets. The current version of RAxML being used at TACC is the Pthreads (POSIX Threads Programming) version. For optimal performance on TACC’s HPC platform, an MPI (Massive Parallel Interface) version must be improved. The approach being taken is to break down RAxML to components to identify and test the parts that require rewriting for MPI, rather than the less efficient approach of refactoring the entire program. In order the expedite this process, the RAxML group has added Frank Willmore, who is experienced in Pthreads.
The group is implementing MPI in the latest version of RAxML using version 7.04 (which supported MPI) as a guide. This implementation is being performed in incremental steps.
As part of porting RAxML to HPC resources the group has developed a light-weight implementation for building starting trees under parsimony (Parsimonator, available from https://github.com/stamatak/Parsimonator-1.0.2)
The development of HPC version of RAxML (RAxML-light) has been completed and the software has been released as a source code (https://github.com/stamatak/RAxML-Light-1.0.5) and will soon be available as a service running on NSF's XSEDE resources through a collaboration with the CIPRES Science Gateway Portal (http://www.phylo.org/portal2/).
Both tools are available on TACC resources as part of the Computational Biology stack.
Through work with the Data Assembly and Integration working group, the group has released a 55K taxa tree of green plants and has provided the Botanical Information and Ecology network at the National Center for Ecological Analysis and Synthesis with a 100K tree on which extensive ecological data could be mapped. The group is currently working on additional large reference trees and on a perpetually updating tree pipeline.
NINJA/WindJammer
Neighbor-joining is a hierarchical clustering method for inferring phylogenies. NINJA, developed by Travis Wheeler, is a new tool that produces correct neighbor-joining trees much faster than the canonical algorithm; it is able to scale to inputs of the size needed for assembling the “tree of life” for all green plants, but would require months and an very large amount of disk storage space to do so on a single computer.
The goal of this collaboration is to build an MPI implementation of the core algorithm from NINJA, to allow biologists to analyze very large data sets in a matter of hours instead of months. The end product is a new implementation of this clustering method, code named WINDJAMMER and entirely re-written in C. The original version was in Java.
Progress on WINDJAMMER is promising. The original version of NINJA can run a data set of 218,348 species in approximately six days. Recent benchmarking of the MPI version of WINDJAMMER can run the same data set in approximately eight hours. This is a memory intensive computation that involves formidable resources, over 2000 CPUs in this case, because all memory must be in internal RAM. TACC is well equipped to handle such cases.
More recent single CPU benchmarking shows modest speedup for WINDJAMMER versus NINJA using only internal memory (WINDJAMMER does not use external memory). The size of the test cases was limited to up to 20K taxa due to the limitations of available RAM. Because it can take advantage of disk space to externalize memory, NINJA is more suitable for single-CPU usage for larger data sets.
However, multi-processor benchmarking of Windjammer and NINJA (using externalized memory on a single CPU) has WINDJAMMER 23 times faster on the 53K taxa case and 32 times faster on a 218K case. Here the difference is that WINDJAMMER is running strictly in RAM and in parallel and NINJA is on one processor and writing to disk.
Using the 218K case and the MPI interface of Windjammer, it is now possible to read in the aligned sequence data (in Fasta format, 270 MB) and generate the distance matrix in parallel in 2 minutes (120.7 seconds). It can write out the generated matrix in about 12 minutes versus reading in the matrix for tree building in 15 minutes. Windjammer takes advantage of a Lustre file system for fast writing of the large matrix file to disk.
Windjammer can now compute the distance matrix directly from both protein and sequence alignments. Previously, it took 2-3 days to generate the distance matrix for the 218K case with FASTTREE (http://www.microbesonline.org/fasttree/). The generated distance matrix required 400GB of disk storage.
Windjammer support three pair-wise distance calculation dna sequences: basic, and Jukes-Cantor and Kimura two parameter methods for multiple substitutions. Windjammer can also calculate protein distance matrices usuing the BLOSUM45
matrix.
Development of the tool has been completed and a publication is in preparation. An extended abstract has been submitted to the ICCABS meeting in Orlando, Florida, Feb. 3-5, 2011 on work describing WINDJAMMER and its performance.
Tree Reconciliation
The primary goal of the Tree Reconciliation (TR) working group, led by Todd Vision at NESCent, is to develop infrastructure facilitating the reconciliation of gene trees and species trees and making these tools and data available to plant scientists. This working group will also publish reconciliations generated as part of the development process.
Ongoing development in collaboration with the Tree Reconciliation working group and the Thousand Plant Transcriptome project (oneKP) is focused on using the existing phylogenetic tree to address evolution of gene families in “host” species. Work is underway on an iPlant incubator project, described below, to provide a gene-species tree reconciliation service that will reconcile gene families being generated by the oneKP project with the green plant species phylogeny. The oneKP project is also a potential source on input data for the data assembly and integration working group's efforts to feed into the "big tree" analysis.
The tree reconciliation service prototype was transitioned to an incubator project in order to accelerate development and bring in various team members with appropriate, specialized skill sets to work on different components concurrently. The tree reconciliation service will provide an interactive web portal in the iPlant discovery environment, through which scientists can explore gene clusters (families), gene trees and reconciled gene trees through a variety of entry points such as gene name searches, a BLAST interface and gene ontology (GO) term-based services. The first version will contain pre-computed reconciliations for over 2500 gene families in six examplar species (poplar, grape, cucumber, papaya, soybean and Arabidopsis thaliana). Subsequent releases will include more species and the ability to perform reconciliations "on the fly".
Significant progress has been made with an analytical pipeline that performs multiple sequence alignments for the initial set of 2,541 gene clusters for six species: soybean, papaya, cucumber, poplar, grape and Arabidopsis thaliana. The pipeline then assembles gene trees and reconciles them with the known species tree.
The sequence alignments are performed using MUSCLE from the European Bioinformatics Institute. Then, species tree-guided gene trees are built with TreeBeST (Figure 1). Finally, tree reconciliation and "fat tree" rendering are performed using PrIMETV (Figure 2). Sheldon McKay is also working on an HPC pipeline to use species-tree guided Bayesian analysis of gene trees using primeGSR.

Figure 1 A gene tree produced by TreeBeST using one of the oneKP gene clusters, rendered in PhyloWidget. Red nodes indicate duplication events, blue nodes are speciation events

Figure 2 The gene tree reconciled with the species tree using PrIMETV
The bioinformatics pipeline for gene-species tree reconciliation is complete and the database has been populated with the reconciled trees and the host-tree relationships. Jamie Estile has written a BioPerl TreeIO module for parsing Newick trees extended with PRIMETV annotations and has pushed it back to the BioPerl repository. We are using an extended version of the Ensembl/compara database schema and associated Perl API. Sheldon McKay and Jamie Estile have been working on the bioinformatics and data modeling and members of the core team are working on the user interface and data interface layer.
Species-guided Gene trees and tree reconciliations are pre-computed for the first release, but later iterations will include larger numbers of species and provide the ability to do reconciliations on the fly. Jamie Estile and Dennis Roberts are paired; working on the SQL queries necessary for the database searches and associated changes to the Perl API. A developer preview release has been completed with the following features:
- Database containing reconciliations for over 2500 gene families in six examplar species (poplar, grape, cucumber, papaya, soybean and Arabidopsis thaliana).
- GUI with the ability to:
- Search by Gene Identifier or GO term
- Perform BLAST searches
- Visualize reconciled trees
- Retrieve and visualize speciation and gene duplication events
- Provide overall statistics and links to alignment and sequence files
A proof of concept was released on March 11th as part of the 0.3 release of the Discovery environment.
Preliminary TR use case
a preliminary TR use case is available on the wiki at:https://pods.iplantcollaborative.org/wiki/display/coresw/Use+Case+Tree+Reconciliation+Version+1
Phase 2 and the Marquis publication
The working group has started discussing the scope for Phase 2. Cooperation with tree visualization group has been intensified with the goal to add interactivity. The initial scoping for this project is available on the wiki at the following location:
https://pods.iplantcollaborative.org/wiki/display/coresw/Discussion of scope for TR version 2.0
This effort involves the coordination of work being done by developers at TACC (Adam Kubach) and the University of Arizona (Andrew Muir and Dennis Roberts )to provide interactions between a gene and species tree. Additional work is being done by James Estill (University of Georgia) to populate the database with the outputs of the pipeline generated by Sheldon McKay for the first project. The goal for this project is to provide a unique view of a gene and species tree reconciliation that will allow for discoveries as they relate to the 1KP datasets.
In addition to the interactive trees being provided with this project, users will be able to search from the species tree for gene families of interest by selecting points of reference from the species tree. The original searches provided will continue to be available as an "advanced search" option.
The development of the TR Phase 2.0 has reached code completion in the 3rd week of February 2011 and will undergo UAT during the 4th week. The delivery to the working group is planned to for February 28th. The features present in this release include:
- Display of species trees and gene trees side-to-side, using the Tree Visualizer developed by the Tree Viz Group.
- Interactive mapping of duplication and speciation events between gene and species tree and vice versa
- Markups for speciation and duplication events on the gene tree nodes and of duplication events on the species tree branches.
- Ability to add additional markups
- Contextual menus
- Advanced search functionalities, including** BLAST** GO terms and accessions** Gene ID
- GO tag clouds for gene families
- Retrieval of underlying data (sequences and reconciliations)
Work continues on the Phase 2.0 version, which is in advanced state of development. The working prototype has been made available to the working group and their feedback is being integrated and the source code is publicly available from GitHub. For the 0.9 release the following functionalities will be implemented:
Support for consensus reconciliations
Orthology display
Allow for choice of reconciliation
Number of duplications on species tree branches
Markup for sequenced genomes.
As well as analytical pipelines using PrimeTV, PrimeGSR and RAxML + NOTUNG.
Development is continued by Jamie Estill, Sheldon McKay and Naim Matasci, with support from Juan Antonio Raygoza Garay for the user interface. The progress is mostly focused on building and evaluating different pipelines, include one that uses an unpublished software (PHYLDOG, in collaboration with the author, Bastien Boussau) but has slowed down recently mainly due to delays with the data production from the 1KP consortium.
Tree Reconciliation Ontology
The group recognized the necessity of being able to store and transfer reconciliation information, but no file format exists that would reliably accomplish this goal. Together with NESCent and under Jamie Estill's leadership, Daniel Packer, a Google Summer of Code participant, has developed a Tree Reconciliation Ontology and worked on a prototype implementation by extending the NeXML file format. Importantly, such an extension can be used to power iPlant's tree reconciliation viewer. This work was accomplished with extensive involvement of the phyloinformatics community (including Rutger Vos, the author of NeXML, Bill Piel, Arlin Stoltzfus, Hilmar Lapp). The project documentation, including repository links and final report is available here. A manuscript describing the ontology is in preparation.
Trait Evolution
The goal of the Trait Evolution (TE) working group, led by Brian O'Meara, is to develop infrastructure to support analysis of traits with reference to established species' phylogeny. An example of such analyses is mapping biotic traits like floral morphology and abiotic information such as geographic ranges on to species trees. The first component consists of a phylogenetic independent contrasts (Felsenstein, 1985) service that is included in the initial release of the Discovery Environment. The TE working group is actively working on defining future development priorities, which include support for the following methods: discrete ancestral state reconstruction (Pagel 1994 character correlation), fitting models (OU, BM, and so on, including various stretching models like those in Blomberg et al. 2003), continuous ancestral state reconstruction. We expect that the BIEN collaboration will provide great addition of expertise in "taxonomic intelligence" and also a rich source of ecological trait data that will benefit from the analytical services being developed by the TE working group. This working group was on hiatus for a few months but has been re-activated with the hiring of the new ETA Naim Matasci. The group opted for the implementation of functions from the R packages ape and geiger that implement the methods identified as a priority by the working group. Additionally, if necessary, the group will also consider and review other implementations. The execution framework to support R scripts has been developed and discrete and continuous ancestral character reconstruction methods are currently being integrated into the Discovery Environment through the ape function ace. The model fitting functions of the package geiger are currently being investigated and the working group has started collecting other methods to provide additional tools.
Through the integration work, the member of the group identified and provided a patch for a serious bug in the function ace (package ape, Paradis, E., Claude, J. and Strimmer, K. (2004) APE: analyses of phylogenetics and evolution in R language. Bioinformatics, 20, 289--290. Cited 314 times) that might have caused unreliable results. The group is also actively working in collaboration with the original author to adapt the package geiger to a HPC environment. As part of this process, Jeremy Beaulieu improved the performance of a key function resulting in a >180X faster execution.
The Discovery Environment now contains over 20 tools to perform phylogeny-based analyses and tree estimation and the working group members can now independently integrate their own tools into the DE. Furthermore, this group is a beta tester for the foundation API that allows them to run and integrate HPC applications.
Optimization routines in R
The progress with the integration of several R-based tools has been delayed by the discovery of serious reliability issues associated with some of the numerical optimization routines. These routines are often used by default in many phylogenetic packages which pushed the group towards starting a sub-project aimed at addressing this issue. The working group believes that an assessment of the optimization routines could lead to recommendations that would benefit the entire phylogenetics community if not the larger life science community that rely on R. The work for this sub project is being done by Kurt Michels, a graduate student in statistics at the University of Arizona and a publication is in preparation.
Tree Visualization
The Visualization (Viz) working group, led by Karen Cranston at NESCent is in its early stages. The high-level objective of this group is a tool that will take tree description input of up to 500,000 leaf nodes, their labels, and edge lengths and display a tree that allows user interaction. The user will be able to browse, zoom, select, search and annotate, while preserving the input information. Browsing will balance between capturing the size of the overall phylogeny and keeping the displayed tree, labels and lengths readable. Zooming will reveal additional information and not simply change the scale of a static image. The user will be able to select single nodes or groups of nodes and add annotations such as text labels, colors or images, either manually or from a file. There will be output options to export a static image that could be used in a publication or presentation. This group has already developed a promising prototype tree viewer (figure 1) that can display hundreds of thousands of species using a bird’s eye overview and semantic zooming effects. The prototype also supports meta-data driven display effects such as node and branch coloring and gradients. This is a cross-cutting working group whose tree viewers will form components of other working groups software, including the tree reconciliation group and the trait evolution working group.
A

B

Figure 3 a) The prototype big tree viewer showing a subset of 100,000 species from the NCBI taxonomy. The inset panel on the left shows the whole tree and the area of focus in the blue rectangle. The main view uses resolution-specific semantic zooming; branches too dense to display are rendered as triangles that can be expanded by clicking on them. Both trees can also be navigated by clicking on the nodes. b) An example of meta-data driven visual effects displayed in a circular layout on the tree viewer.
The Tree Visualizer has reached maturity and was demoed to the Trait Evolution and Tree Reconciliation working groups. Among the most important improvement is the addition of a sidebar menu to change visual properties of nodes and edges and the interactive capabilities. Both groups were impressed with the tool's performances and the Tree Visualizer was adopted to display tree reconciliations by the TR group. Work with Core Software ensured the integration of the Viz Tool in the Discovery Environment.
The work is now focused onto releasing the tree viewer as a standalone product.
Data Assembly and Integration
This was originally two working groups that merged in January 2010. The goal of the Data Assembly and Integration working group, jointly led by Pam Soltis, Doug Soltis, Michael Donogue and Val Tannen, is to develop a prioritized list of phylogenetic data sets and tools to guide the assembly of the data matrix required for the phylogenetic inference being performed by the Big Trees working group, described below. The activities of this working group are fundamental for iPToL, not only for data assembly, but seeking input from the phylogenetics community at large to ensure that iPlant continues to develop a cyberinfrastructure that addresses the needs laid out in the tree of life grand challenge proposal and subsequent grand challenge team discussions. The first step in this process was hosting the data assembly workshop held in November 2009. This meeting brought together stakeholders in the plant phylogenetics and analysis communities to discuss priorities and strategies for assembling data for the marquis "big tree" analysis that will form the foundation of the iPToL discovery environment.
This meeting of ~50 community members and iPlant staff and faculty focused on identifying data resources that will feed iPToL's "big tree" analysis and the iPToL discovery environment. The workshop brought together evolutionary biology research community leaders (the data producers) with members of the methods-focused analysis community who contribute expertise in data acquisition and interoperability. Another outcome of the workshop was a consensus “wish list” of cyberinfrastructure components the group felt was essential to the success of iPlant. Two items on this wish list have already been developed and deployed: a phylogeny-guided social network and a data ingest pipeline. Others are in process.
Data Assembly Meeting Outcome: CI wish list
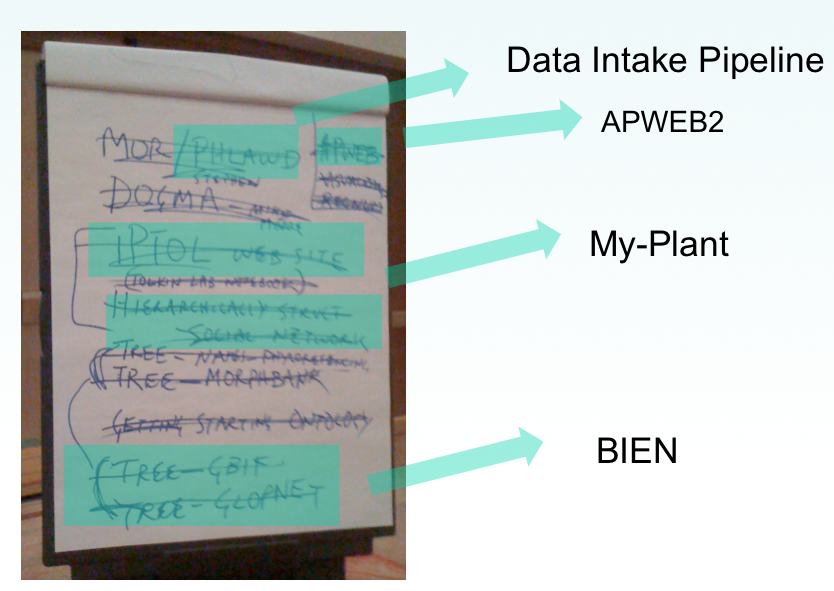
Figure 4 The condensed CI wish list from the November "Data Assembly" meeting in Phoenix.
My-Plant.org
My-Plant.org is a phylogenetically-structured social networking website under development for plant scientists, educators, and other interested parties. It is now live at http://my-plant.org. Users will be able to easily share information and research, collaborate, and stay on top of the latest news in their field. Members of the My-Plant.org community will gather around clades of choice, then view and contribute to information surrounding the clades including image galleries, message board discussions, wiki pages, clade pages, and access to external sources of data. My plant was launched and announced this summer at the ASPB meeting in Montreal and the Plant Biology Meeting in Boston.
In March 2011 the website underwent a major upgrade. The key items include a much improved posting interface and new backend structure to allow for more flexible association of groups/topics.
My-Plant Goals:
- Foster communication and collaboration among plant scientists
- Discover and highlight novel connections in clades, species, and their data
- Promote the use and awareness of iPlant services and infrastructure
- Become a community for education, outreach, and training
My-Plant Features:
- Selectively join clades at any level
- Browse phylogenetic trees to discover clade relationships
- Message boards for discussions
- Links to iPlant Discovery Environment and Big Tree Viewer
- Clade-specific links to Tree of Life, NCBI, Encyclopedia of Life, and TreeBase
- Utilizes web services for data integration and syndication
- Extensible and flexible for growth and evolution of features
Data Ingest Pipeline
The goal of this project is to establish a robust data pipeline that makes use of different methods to compare and cluster sequences, identify orthologous genes and compute multiple sequence alignments as well as gene trees. The group has begun implementing several approaches to move efficiently from sequences to gene trees. The PHLAWD data intake pipeline,developed by Stephen Smith, takes predefined gene regions of interest and exemplar sequences representing phylogenetic diversity, it does not require clustering. The All-by-all BLAST pipeline, developed by Gordon Burleigh, offers the advantage of not requiring any a priori functional knowledge. Sharon Wei (Cold Spring Harbor laboratory) has been testing pipelines in a development environment and work is in progress to migrate them to the HPC environment at TACC.
The objectives of the data integration part of the working group are crosscutting in nature. Data integration and interoperability touch all aspects of the tree of life grand challenge, from initial data entry through analysis and dissemination of analytical results. The DI working group is actively discussing integration issues that face all of the other iPToL working groups and collaborations. This group is actively assessing current integration and interoperability issues as well as anticipating those that will arise in future. The considerable expertise of this group in database and phylogenetic software design is also being leveraged to contribute to high-level design of the discovery environment infrastructure. Collaborations with two external groups also impact the operations of the working group. The first concerns the overarching need for a "taxonomic intelligence" solution, which addresses the highly complex task of mapping species identifiers across various alternative taxonomies, synonymies, data entry errors, homonyms, etc. The DI group has developed a prototype name resolution service, which is now being expanded as a consequence of the relationship with the BIEN group. Members of the DI working group attended a BIEN workshop at NCEAS that led to the ongoing BIEN collaboration and taxonomic name resolution service project (discuseed below).
The DA group in collaboration with the Big Trees group has developed a data ingest pipeline (Perpetually Updating Trees) that will regularly retrieve sequences from public repositories (NCBI), use these to build large phylogenetic trees and make these tree available to the community through the DE.
BIEN-iPToL
The BIEN-iPToL working group is a new collaboration with the National Center for Ecological Analysis and Synthesis (NCEAS) Botanical Information and Ecology Network (BIEN) working group to address three primary areas of synergy with iPlant (see https://pods.iplantcollaborative.org/wiki/display/iptol/BI_Project_Charter for details):
- Taxonomic intelligence
- Mapping biotic and abiotic traits to phylogenetic trees
- A plant observation database, which currently houses ~ 25 million records
Taxonomic Intelligence or Name Resolution Service
The iPlant Collaborative Incubator Project to create a Taxonomic Name Recognition Service was demonstrated on October 20, 2010 as a stand alone application with intentionally limited functionality. This preview is capable of reconciling a list of up to ten names that are input directly into the application with names from a database constructed using data from Tropicos. Users are able to inspect matching results and make decisions from among multiple options when more than one possible match is returned for a submitted name. The ability to upload a file with a longer list of names is coming soon and there are plans for significant speed optimizations. With the planned integration into the Discovery Environment, the ability to perform unsupervised batch processing of lists and easy methods of using the results of the reconciliation as input to other scientific tools in the DE.
The creation of a tool chain that starts with the GNI Parser from Global Names Index for exact name matching and combines it with a tool called Taxamatch for fuzzy matching has enabled the implementation of a more complete resolution solution. While this works in the preview, speed optimization is desired for a release and this is being explored.
Future plans include transforming non-accepted names included in the Tropicos database dump into accepted names. In addition, new data sources including APG III and Kew classifications and names and classifications from USDA plants database will be added. After that, the ability for a user to submit Family and match taxa below the rank of species will be added through a modification to the Taxamatch code.
While the work on the stand alone preview has been done (accessed here: http://tnrs.iplantcollaborative.org/), iPlant Core Software has also done some work on the creation of the Discovery Environment UI, the supporting RESTful services, and a database loader tool. In the DE integrated version, not yet available for preview, the ability to enter a list directly into the UI for analysis has been incorporated (Figure 1) as well as the ability to upload a .csv file and select it for analysis (Figure 4). Work is being completed on the incorporation of the backend tools while the services for displaying (Figures 5 and 6) and downloading results are being finalized.
A use case for TNRS is available on the wiki at:https://pods.iplantcollaborative.org/wiki/display/IP/TNRS+Use+Case+Release+1
The work on the first iteration has been completed and the group moved to Project 2, which involves the ability to resolve synonyms and higher and lower taxonomic ranks (family and infraspecific epithets). As part of this effort Jerry Lu has started working on a refactoring of the TaxaMatch code and the improvements to the GNI parser together with the original authors of these tools (Tony Rees of the CSIRO Marine and Atmospheric Research and Dmitry Mozzherin from the Encyclopedia of Life, respectively). Improvements to the code resulting from this effort have already been pushed back to the community as part of these tools' releases.
The second iteration is now ready for release and will include the ability to restrict searches by taxonomic groups, a more fine grained control over the resolution as well as many performance improvements and bug fixes. Development for multiple source support is well underway with a development prototype containing both Tropicos and the NCBI taxonomy is already available. An agreement with the Global Compositae Checklist will also allow that list to be available.
Members of the working group participated in the Nomina IX to discuss the Global Names Architecture vision and plans. In particular, we are collaborating with Dmitry Mozzherin who is the GNA's chief architect and offered the TNRS as a plant-specific prototype for a global name resolver. The planned global names resolution service will allow the extension of iPlant's TNRS beyond plants only. A publication describing the TNRS is in preparation.
Mapping biotic and abiotic traits to phylogenetic trees
The 110K tree produced by the Big Tree working group could be linked to ecologic traits thanks to the TNRS. It is by far, the best-resolved phylogenetic tree available for biodiversity and ecology studies of plants in the western hemisphere. Four publications using this tree are in preparation by members of BIEN.
Range maps
Using HPC resources it was possible to compute range models for ~30,000 species in 6 hours. The group is now expanding to 120,000 North American plant species which would have taken over a year to compute on a single machine.
The preliminary range maps are already providing insights into
- How many plant species are rare
- Efficacy of modeling methods
- Range size vs. abundance
- Distribution of range sizes
Other Collaborations
Angiosperm Phylogeny Website
A collaboration is planned between iPlant and the Angiosperm Phylogeny Website (Peter Stevens, Cam Webb, Amy Zanne) to modernize the infrastructure and convert the current static HTML pages of APWEB into dynamic database-driven web services (APWEB2) that will offer these widely used data to researchers and educators using a variety of different interfaces. Funding is in place and hiring is underway. Nirav Merchant has also offered support from University of Arizona graduate students to help a build Drupal-based web interfaces for the new databases. Work will commence when the developer is hired at the Missouri Botanical Garden.
Support for 1,000 Plant Transcriptome Project (1Kp)
At a meeting jointly sponsored by iPlant and NESCent, held November 2009 in Phoenix, a computational working group was organized to perform the following tasks:
- Organize the transcriptome data into gene family sets
- Create alignments and gene tree estimates
- Develop searchable gene family database
- Estimate species relationship from supertree and supermatrix analyses of the gene family trees and alignments
The attached PDF describes the planned analyses. Results will be made available to everyone in the consortium. It will take a bit of time to set the permissions so everyone in the 1KP consortium can access the wiki.
The computational working group will ultimately be responsible for producing the phylogenomics of all 1000 species, but anyone in the 1KP consortium is welcome to contribute or perform alternative analyses. Data produced should not be redistributed beyond the consortium as this might sabotage the 1KP publication plans. The plan is to have one or more high profile phylogenomics papers, and in particular an omnibus paper on all 1000 species, and more specialized papers on each subproject as described at the 1kp web site at www.onekp.com. In addition, the group hopes to publish a paper on a “deep green” pilot analysis of 90-100 taxa.
Currently, 850 transcriptomes have been assembled and undergone family circumscription.
New models of collaboration
In response to feedback from the iPToL leadership, the iPlant engagement team has introduced two new models of collaboration that address concerns about the rate of progress and the desire of external collaborators to have more direct access to the developers.
TACC
The Texas Advanced Computing Center (TACC) has a large pool of skilled software developers and HPC experts to draw from. Developer/analysts and students with the right skill sets were allocated to several TACC-based iPToL projects. These developers worked in project-focused groups under the supervision of Michael Gonzales, who has transitioned from project manager to product manager. Sheldon McKay provided overall scientific leadership and outreach for all iPToL working groups until Naim Matasci took over the Scientific Lead positon.
University of Arizona
Sonya Lowry, as Director of Cyberinfrastructure Development, and Sheldon McKay have introduced a new model of collaboration that brings members of the engagement team, development leadership and staff and working group members into direct contact to facilitate rapid requirements analysis and development of focused projects. This model was used for the development of the Tree Reconstruction platform and is still used for the TNRS project.
Source code
The source code for some projects is available via git or subversion repositories:
- Big tree viewer (working name phyloviewer)
- WINDJAMMER [access restricted to iPlant account holders]
- Tree Reconciliation + library
- Taxonomic Name Resolution Service
- Parsimonator
- RAxML-Light
Additional development source can be viewed at the iPToL subversion repository
All publicly released open source code can be accessed at the iPlant OpenSource repository on GitHub